We are going to a same word-counting task as we did here, but this time with Cloud Dataproc. Dataproc is perfect for migrating from existing big data solution such as Hadoop / Spark workflow to Google Cloud. It leverage the advantages of Cloud platform where processing power can be requested as needed and store data off-cluster.
Pre-requisites:
- Enable dataproc API
- Create a GCS bucket
1. Clone our working file
We are going to need the wordcount python program to execute the counting and the Macbeth screenplay text file for us to count the words. Let’s cloud these files in out Cloud shell.
git clone https://github.com/GaryYiu/gcp-resource.git cd gcp-resource/dataproc_demo

We can see both of the files are in the directory.
2. Create the Dataproc cluster
We can create the cluster either in the console or with Cloud shell. It is more straight forward to use cloud shell with just a single line of code
gcloud dataproc clusters create wordcount --region=asia-east2 --zone=asia-east2-a --single-node --master-machine-type=n1-standard-2
Pick a region and zone that is close to you for faster connection. For this simple demo task we only need basic processing power. It will take a while for the cluster to create. From the Dataproc console, we can see the cluster being created.
3. Submit the Pyspark job
Now we have the cluster created, we can submit the Pysprak job for the cluster to run the word count.
gcloud dataproc jobs submit pyspark wordcount.py --cluster=wordcount --region=asia-east2 -- \ gs://dataflow-samples/shakespeare/macbeth.txt \ gs://gary-test-quick/output/
Here the Pyspark job is taking the text file in one GCS as input and it will store the output in our designated cloud storage. We can go to Dataproc, navigate to Job page, we can see the job we just submit is running and will be finished in fairly short time.

4. View the output
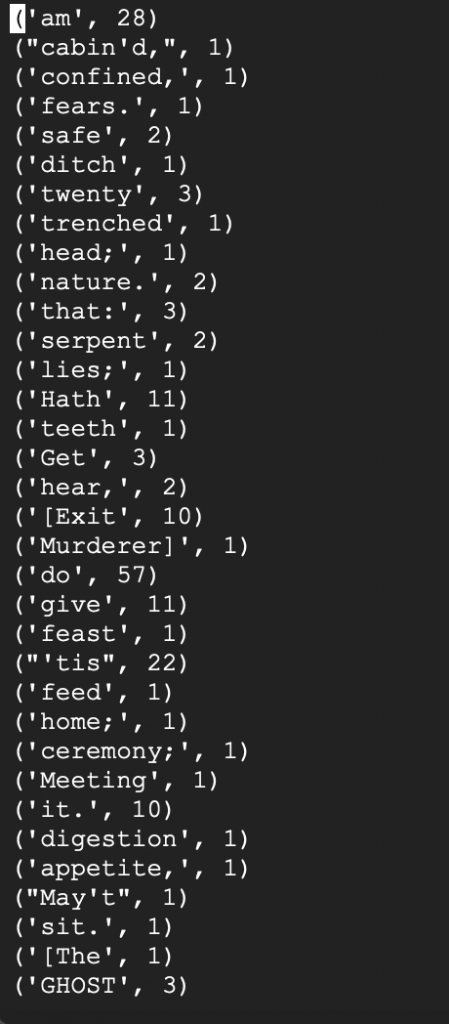
gsutil cp -r gs://gary-test-quick/output . cd output vim part-00000
We can see our output file as follows.
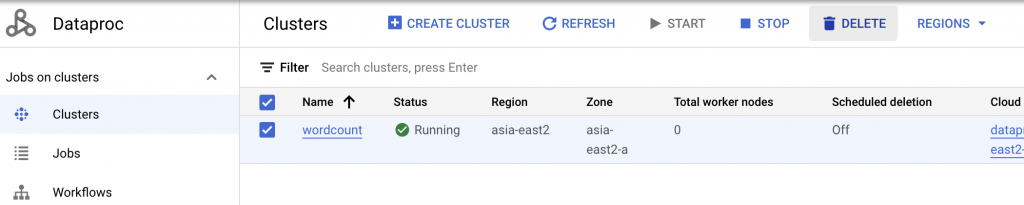
To conclude, let’s wrap up by terminating our Dataproc cluster. Navigate to Dataproc page and delete our cluster.