

We are trying to create a Cloud Dataflow pipeline to do a simple work count on any kind of text file. We’ll be using a wordcount function that is included in the apache_beam SDK package. It basically takes any text file and parse each lines into words, then perform a word frequency count.
Prerequisites:
- Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs
- Create a new Cloud Storage bucket
We’re going to use the Cloud Shell to create the pipeline so no need to set up a virtual environment
1. Get Apache BEAM SDK
Install python wheel
pip install wheel
Install latest BEAM SDK
pip install 'apache-beam[gcp]'
2. Run the pipeline locally in Cloud Shell to test
python -m apache_beam.examples.wordcount \ --output output-test

Click ‘Authorize’ when asked by Cloud shell. The code by default run the word count on the Shakespeare’s play King Lear. After the run is finished we should see a output-test file created in our directory.
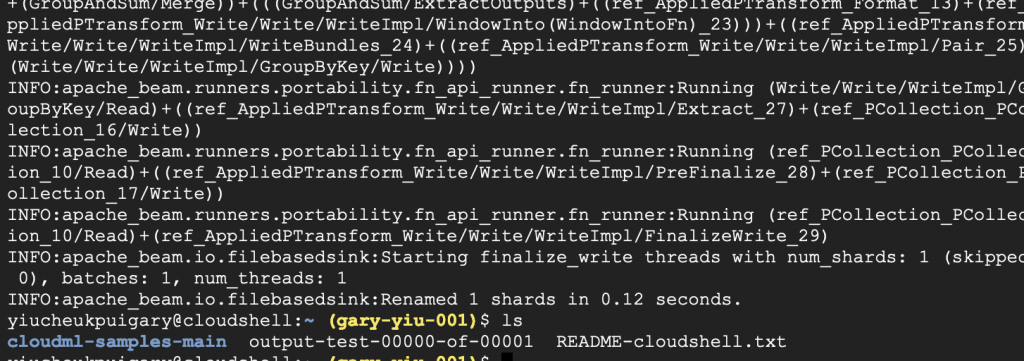
Use `vim output*` to view the output file you’ll see it counts the words appearance and list it out in the file.
3. Run the pipeline on Dataflow service
For demonstration, we are counting words from another Shakespeare’s play Macbeth. Enter the following code to your Cloud console.
python -m apache_beam.examples.wordcount \
--region asia-east2 \
--input gs://dataflow-samples/shakespeare/macbeth.txt \
--output gs://bucket-for-quickstart-gary/results/outputs \
--runner DataflowRunner \
--project gary-yiu-001 \
--temp_location gs://bucket-for-quickstart-gary/tmp/

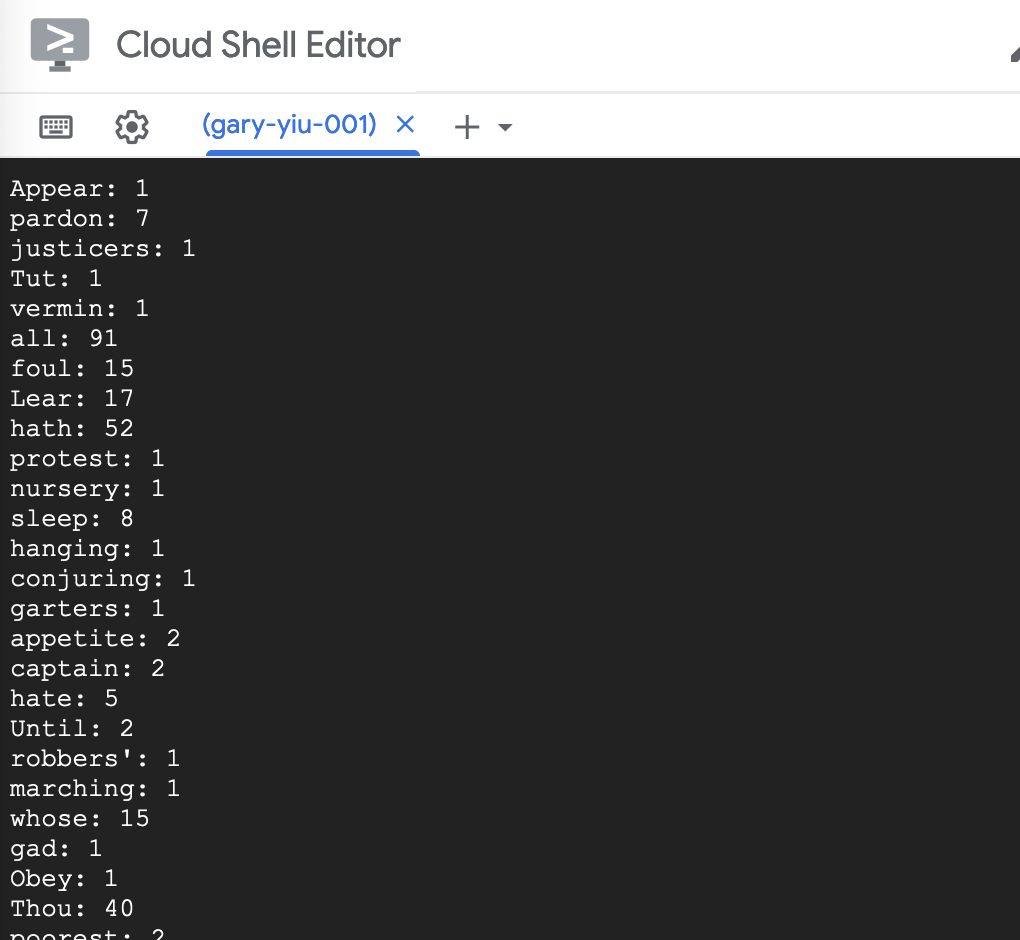
Google cloud will then create the Dataflow job and the necessary resources to run the job. Go to Airflow from drop down menu, we can see our Dataflow job was created.

Click into the job name, we can see the details and each stage of the job. Also the resources that are being used are displayed.
After the job is done, we’ll get the following message in the Cloud console. We can go ahead to our bucket to see the output of the job.

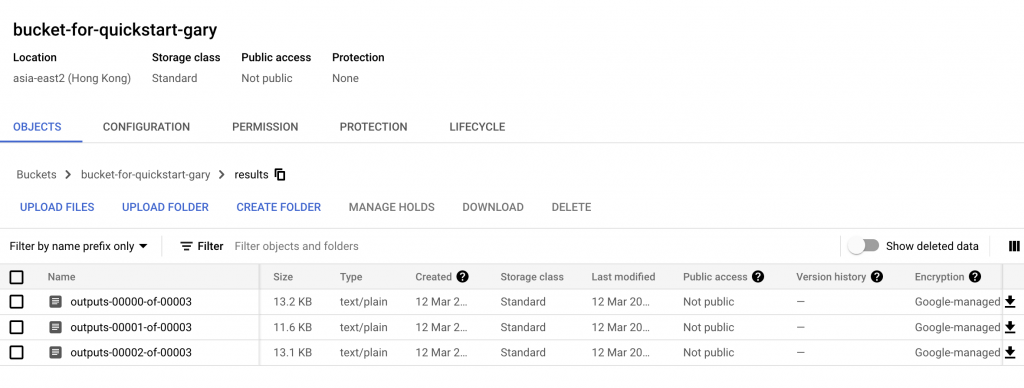
Copy the output text files to our Cloud console to take a look of the content
gsutil cp gs://bucket-for-quickstart-gary/results/* . vim outputs-00001-of-00003
Now we can confirmed we successfully built our Dataflow pipeline 😀 Remember to delete our bucket to avoid unnecessary cost.



